Tad Hunt
tad@csh.rit.edu http://www.csh.rit.edu/~tadAndrew Kitchen, Professor
Rochester Institute of Technology, Rochester, NY
Parallel Algorithms and Program Design
19 May 1996
Of the many issues parallel algorithm designers must take into account, data distribution is among the most important. Often, the size of the data set will be larger than available memory, so the distribution of the out-of-core dataset across nodes and disks and the out-of-core data access patterns will have a significiant effect on speedup. This paper looks at three parallel software systems designed to minimize parallel file access overhead: PASSION and Jovian for SIMD processors, and Disk-directed I/O for MIMD processors. It compares and contrasts the techniques and results of each paper, focusing on the increases in performance of various algorithms using the techniques described.
Many parallel applications operate on datasets much larger than available memory. Such applications can benefit from decreasing the time spent loading the data from disk into memory. Of the many issues parallel algorithm designers must take into account, data distribution is among the most important. Poor distribution can drastically increase the total time spent performing the computation. The distribution of the out-of-core dataset across nodes and disks and the out-of-core data access patterns will have a significant effect on speedup.
Parallel applications usually have different disk access patterns than is found in typical uniprocessor systems. Many multiprocessor machines have parallel filesystems derived from Unix which makes porting applications easier for the programmer, but often results in poor performance. The Unix filesystem was designed for general purpose access rather than the type of access found in parallel scientific applications. For example, parallel scientific programs have larger files and more sequential access. They also typically use complex strided access to Dis-contiguous pieces of the file. Additionally, large scratch files are often used as application-controlled virtual memory for problems too large to fit into physical memory. [DK94]
Two approaches to parallel file I/O are parallel file systems, and partitioned secondary storage. There is a rough correspondence between these two types of parallel I/O and shared and distributed memory. Parallel file systems, in one mode, mirror shared memory, and partitioned secondary storage mirrors distributed memory. Using either of these two methods will be more complicated than making use of the virtual memory resources provided by the operating system, but the benefit is quicker access to needed data.
Parallel file systems operate in two modes. A single file can be distributed across multiple disks on multiple I/O nodes. If there are more I/O nodes than compute nodes, the result can be an improved disk-to-memory transfer rate. However, the opposite is usually true, in which case the transfer rate is decreased because of overhead such as contention for service. Parallel file systems also operate in a mode where each file is shared by all processors and is distributed across all I/O nodes. This method is similar to shared memory, and shares its advantages and disadvantages.
Partitioned secondary storage consists of a system in which each processor has its own logical disk that no other processors have access to. Access to this data must occur through the processor to which the logical disk belongs. Essentially, it is identical to distributed shared memory in that respect. Note that using partitioned secondary storage is more complicated than using parallel file systems, though the potential benefits are much greater. Since the logical disks can be treated as local secondary storage, the programmer can control the format and the locality of the data stored there to match the computational requirements. Also, the programmer can plan how to overlap computation and I/O to minimize delays during communication. [WGR+93]
This paper looks at three parallel software systems designed to minimize parallel disk I/O overhead: PASSION and Jovian for SIMD processors, and disk-directed I/O for MIMD processors. It compares and contrasts the techniques and results of each paper, and discusses the speedup of some simple algorithms using the different parallel I/O implementations described.
PASSION provides software support for high performance parallel I/O. It provides this support at the language, compiler, runtime, and file system level. I'll be focusing on its runtime support for out-of-core computations. One of the goals of the PASSION design is architecture independence. Therefore, the only architectural requirement is any distributed memory computer with some sort of an interconnection network between processors. The set of disks can either be shared amongst the nodes, or each node can have its own local disk. The I/O nodes may be either dedicated or compute nodes. Finally, the I/O routines were implemented using the native parallel file system calls provided by the machine. This means that the PASSION system is portable to an extremely wide range of distributed memory SIMD and MIMD systems.
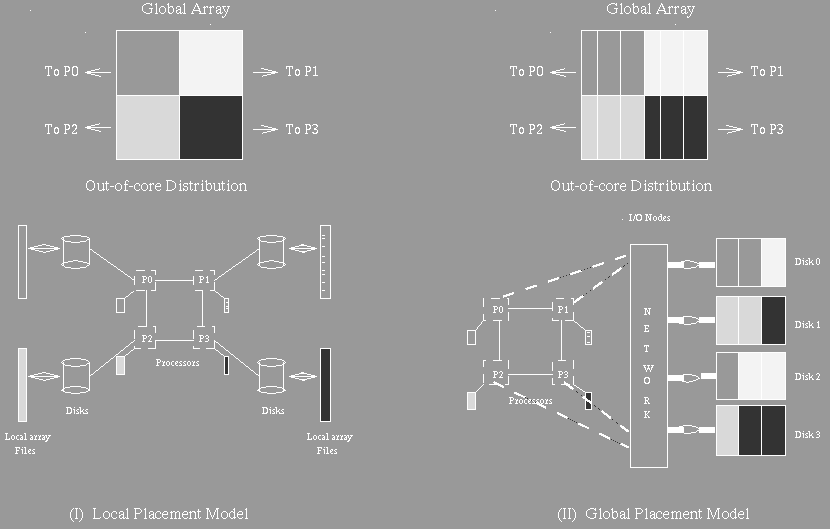
The PASSION system provides three different storage models to support different algorithmic needs. The basic storage type is array. The models are called the Local Placement Model (LPM), Global Placement Model (GPM), and Partitioned-Incore Model (PIM). The runtime system transparently handles the reading and writing of data in the three models.
The Local Placement Model (LPM) divides the global array into local arrays belonging to each processor. Each processor stores its local array in a separate file called the Local Array File (LAF). Essentially, this model provides each processor with another level of memory which is much slower than main memory. Each processor is assumed to have a logical disk, as in [WGR+93] (as mentioned in the introduction). At any given time some portion of the local array is actually in memory. This is called the In Core Local Array (ICLA). Most algorithms using the LPM will roughly correspond to the template shown in figure 1.
+---------------------------------------------------------------+ | DO | | load next part of the array into the ICLA | | perform computation | | store ICLA | | REPEAT | +---------------------------------------------------------------+Figure 1: Standard algorithmic template using the Local Placement Model (LPM)
The Global Placement Model (GPM) stores the global array in a single file called the Global Array File (GAF). The runtime system fetches the appropriate portion of each processors local array from the GAF. The advantage of this model is that the cost of the initial local array file creation is saved. The disadvantage is that access to the GAF may not be contiguous, resulting in longer I/O times. Additionally, synchronization must occur when a processor needs to access data belonging to another node.
Figure 2: Local and Global Placement Models [CBH+94]
The Partitioned-Incore Model (PIM) is a variation of the GPM. The global array is logically divided into a number of partitions, each of which can fit into the main memory of all the processors combined. This causes each computation on the nodes to be an in-core problem, so no I/O is required during the computation. The runtime system distributes the data among the processors using the Two-Phase Data Access Method (described later). This model is useful when the data access pattern has good locality.
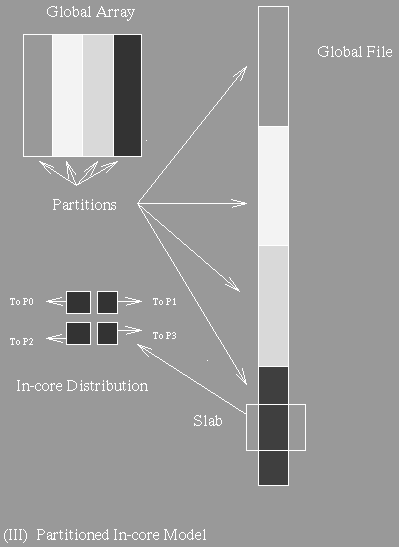
Figure 3: Partitioned-Incore Model [CBH+94]
There are two types of out-of-core problems; structured and unstructured. The PASSION system supports both kinds. In unstructured problems, the data access patterns cannot be predicted until runtime. This means that many compile-time optimizations are useless. However, during runtime, the data access patterns of a loop-nest are usually known before entering the nest, making it possible to do some preprocessing. Software caching and communication vectorization can be performed. The PASSION runtime system does this. Such unstructured computations are integral to many applications in fluid dynamics, molecular dynamics, and diagonal or polynomial preconditioned iterative linear solvers, among others.
One of the algorithms used to test the PASSION system was a Laplace equation solver using Jacobi iteration. Figure 4 shows the algorithm. The arrays are distributed as blocks (rather than rows or columns) on a 4x4 grid of processors. The value of each element of A is calculated from the four surrounding B values. To calculate the values at the four boundaries of the local array, each processor needs the rows or columns of its neighboring processors. Since the local array is out-of-core, data from the LAF is read into the ICLA, and new values are computed. At the end of each iteration, processors need to exchange boundary data with neighboring processors. If the data is in-core, all that needs to be done is communicate the data to the node that needs it. If the data is out-of-core then either the processor can directly read the other processors' LAF (Direct File Access Method), or by using the Two-Phase Approach mentioned earlier.
The performance of the Laplace equation solver is given in table 1. The numbers are from Intel's Delta using the Concurrent File System with 64 disks. The array is distributed in one dimension along columns. Notice that the direct file access performs the worst because of contention for disks. The best performance is obtained for the two phase method with data reuse because it reduces the amount of I/O by reusing data already fetched into memory. If the data is distributed in both dimensions, the performance of the direct file access is expected to be worse because four processors will be contending for a disk when they try to read the boundary values.
+---------------------------------------------------------------+ | parameter (n=1024) | | real A(n,n), B(n,n) | | ...... | | !HPF$ PROCESSORS P(4,4) | | !HPF$ TEMPLATE T(n,n) | | !HPF$ DISTRIBUTE T(BLOCK,BLOCK) ONTO P | | !HPF$ ALIGN with T :: A, B | | ...... | | FORALL (i=2:n-1,j=2:n-1) | | A(i,j) = (B(i,j-1) + B(i,j+1) + B(i+1,j) + B(i-1,j))/| | B = A | | ...... | +---------------------------------------------------------------+
Figure 4: Laplace equation solver HPF program fragment
+-------------------------------+---------------------+----------------------+ | | Array Size: 2K x 2K | Array Size: 4K x 4K | | +----------+----------+----------+-----------+ | | 32 Procs | 64 Procs | 32 Procs | 64 Procs | +-------------------------------+----------+----------+----------+-----------+ |Shift using Direct File Access | 73.45 | 79.12 | 265.2 | 280.8 | +-------------------------------+----------+----------+----------+-----------+ | Shift using Two Phase | 68.84 | 75.12 | 259.2 | 274.7 | +-------------------------------+----------+----------+----------+-----------+ | Shift using Two Phase | 62.11 | 71.71 | 253.1 | 269.1 | | with data reuse | | | | | +-------------------------------+----------+----------+----------+-----------+
Table 1: Performance of Laplace equation solver (Time in sec. for 10 iterations)
The PASSION group studied out-of-core unstructured molecular dynamics and CFD algorithms on an Intel iPSC/860 with 16 compute nodes, 2 I/O nodes, and 4 disks. They used 14K and 6K "atom" sizes for the molecular dynamics example. Table 2 shows that as the slab size is increased the performance improves because the number of I/O accesses decreases. Also, the performance improves as the number of nodes is increased. The best performance is observed for 8 processors with a slab size of 64K. However, as the number of processors increases to 16, performance decreases because the I/O subsystem becomes saturated with requests.
+-----------+-----------------------------------------------+ |Processors | Slab size | | +-----------+--------+--------+--------+--------+ | | 8K | 16K | 32K | 64K | 128K | +-----------+-----------+--------+--------+--------+--------+ | 2 | 194.61 | 190.81 | 188.85 | 187.83 | 190.95 | +-----------+-----------+--------+--------+--------+--------+ | 4 | 134.79 | 129.84 | 127.54 | 130.27 | 138.45 | +-----------+-----------+--------+--------+--------+--------+ | 8 | 115.35 | 99.68 | 94.62 | 92.16 | 98.54 | +-----------+-----------+--------+--------+--------+--------+ | 16 | 127.22 | 109.77 | 107.81 | 111.73 | 107.25 | +-----------+-----------+--------+--------+--------+--------+
Table 2: Performance of Laplace equation solver (Time in sec. for 10 iterations)
This section describes some of the optimizations mentioned earlier, such as data pre-fetching and reuse. Additionally, it introduces an optimization called data sieving which improves performance of reading lots of small bits of data tremendously.
Assume that we wish to access N individual non-contiguous elements of an array. Using the Direct Read Method, we would make N read requests to the I/O subsystem which in turn would make N requests to the filesystem, one for each read. The major disadvantage of this method is the large number of I/O calls, and small size of the data transfer. Since I/O latency is very high, and is approximately the same for accesses up to the size of a disk block, this method is very expensive. They give an example using an Intel Touchstone Delta using one processor and one disk. With the direct read method it takes 16.06 ms. to read 1024 integers as a single block (one request), whereas it takes 1948 ms. to read them all individually.
With data sieving the OCLA (Out-of-Core Local Array) is logically divided into slabs, each of which can fit in main memory (ICLA). Assume we want to read the array section specified by (l1:u1:s1,l2:l2:s2) where l is lower bound, u is upper bound, and s is the size or stride. Using the data sieving method, the entire block of data from l2 to u2 is read into a temporary buffer with one read call. The required data is then extracted from this buffer and put into the ICLA. The major advantage of this method is there is only one read call. The major disadvantages are the large memory requirement, and the extra amount of data read from disk. However, the savings in the number of I/O calls increases performance considerably. Table 3 shows times for direct versus sieved read and write.
Note that writing array sections from the ICLA to the LAF can also benefit from data sieving. The method is similar to storage using a write-through cache. First the block that is to be written must be fetched from the disk, then the values that are being written inserted, then the updated block written out. Assuming the time to write a disk block is equivalent to the time to read a block, one can clearly see that writes will take twice as long as reads.
+----------------------+--------------------------+---------------------------+ | Array Section | READ | WRITE | | +------------+-------------+-------------+-------------+ | |Direct Read | Sieved Read |Direct Write | Sieved Write| +----------------------+------------+-------------+-------------+-------------+ | (1:2048:2, 1:32:2) | 52.95 | 1.970 | 49.96 | 5.114 | | (1:2048:4, 1:32:4) | 14.03 | 1.925 | 13.71 | 5.033 | | (10:1024:3, 3:22:3) | 8.070 | 1.352 | 7.551 | 4.825 | |(100:2048:6, 5:32:4) | 7.881 | 1.606 | 7.293 | 4.756 | |(1024:2048:2, 1:32:3) | 18.43 | 1.745 | 17.98 | 5.290 | +----------------------++------------+------------+-------------+-------------+
Table 3: I/O times of Direct and Sieved Read/Write. 2K x 2K global array on 64 procs. (ICLA size: 2K x 32), slab size = 16 columns.
With the LPM, the OCLA is divided into slabs, each of which can fit into the ICLA. Execution proceeds following the template in figure 1. If it is possible to overlap computation and I/O, issuing an asynchronous read request for the next slab immediately after the current slab has been read can be done. This is called data prefetching. If compute and I/O times are comparable, this can result in a significant performance improvement. For example, the PASSION crew implemented an out-of-core median filtering algorithm using prefetching. In all cases, prefetching improved performance significantly.
The less data that has to be read from the disk, the better the performance of an algorithm. If it is possible to reuse data already fetched into memory, then significant savings are possible. For example, in the Laplace equation solver described earlier can benefit from data reuse by moving the columns (assuming col-major order) in memory over, rather than rereading them from disk. That way, the only disk transfers required are the ones to get new data off the disk.
The two-phase data access method assumes that each processor has access to either a physical or logical disk. The basic idea is that the data is stored on the disk in whichever form gives the quickest access times. During a read phase, the data is read in, then a permutation algorithm is run on it to massage it into the form required by the algorithm. The goal is to end up accessing large contiguous chunks of the file. The overhead of the permutation algorithm is minimal compared to the overhead of non-contiguous access. [BBS+94]
The Jovian library is another software system for parallel I/O. It is intended to optimize the I/O performance of multiprocessor architectures that include multiple disks. The authors include performance statistics from an implementation running on the IBM SP1 distributed memory parallel machine for two different applications.
Similar to the PASSION system, the Jovian system can use either dedicated I/O nodes, or nodes that share responsibility as both I/O and compute nodes. The key objective is to coalesce disk access to minimize the number of requests passed to the disks. The main focus of the Jovian architecture is to optimize parallel I/O.
There are several traditional ways to cut down on the number of disk accesses. Disk caches are perhaps the most widely known. A disk cache maintains a set of recently used disk blocks in- core. It relies on spatial and temporal locality to reduce the number of disk accesses. Prefetching is also used quite often. Basically prefetching consists of reading additional blocks into the cache asynchronously in the hope that they will be used relatively soon.
Single Process Multiple Data (SPMD) algorithms often need to move large data sets from disk to memory. Generally, these data sets are distributed over a group of processors. In addition to distributing the data across the processors, thought must be given on how to distribute the data across the available disks to maximize the data parallelism in loading the data from the disks.
The Jovian library tries to minimize the number of I/O requests by coalescing them into larger contiguous requests. As we have seen in the description of the PASSION system, contiguous accesses give significant savings in access time. The Jovian library uses a varying number of coalescing processes to perform this task. This type of optimization is called collective local I/O optimization.
Generally, a row major or column major array storage method is the most efficient in terms of speed. The time spent in permuting the data between the storage format and the format the algorithm wants is small compared to the access time for noncontiguous data. Essentially, by adding complexity at the software level, the result is a net speedup.
Whereas the PASSION system can support SIMD and MIMD architectures, the Jovian system only supports SPMD programs. Essentially, with this model, each processor runs the same code, but can take different execution paths based on the input data. The Jovian designers chose this limitation to simplify the development of the libraries and applications using it.
Another limitation of the Jovian library is it makes the assumption that that the algorithm will execute in a loosely synchronous manner. Basically this means that the processors alternate between phases of computation and I/O. The implication of this within the context of the Jovian system is that even if a processor doesn't need to do I/O during a given phase, it still has to participate in the I/O preprocessing stage by sending a null request to the I/O library. The PASSION system doesn't have this assumption or requirement.
The parallel applications the Jovian designers plan to implement are from three major areas: Geographic Information Systems, Data Mining, and Scientific. The Geographic systems require the analysis of extremely high resolution satellite data for accurate measurement. The images to be analyzed are on the order of several gigabytes. Data Mining is the technique which infers rules to classify data in a database. Many scientific programs are based on sparse arrays or block structures, and can make use of the Jovian library. The I/O optimizations provided by the library should be able to coalesce the irregular disk accesses to contiguous accesses.
The execution model distinguishes between two types of processes: application and coalescing processes. Each application process issues I/O requests to a statically assigned coalescing process. The mapping can be a many-to-one or one-to-many. Each coalescing process is responsible for a part of the global data structure stored on disk. The job of the coalescing process is to minimize the number of I/O requests by coalescing them into larger contiguous requests.
There are two ways in which application processors can specify the data needed from disk. Range requests consist of a set specified by a lower index, upper index, and stride. For example, if a matrix is block distributed across the application processors, given P application processors, each is responsible for a NxN submatrix. Each processor will request N ranges, one for each row of the submatrix. Range requests are good for structures with small dimensions. However, as the number of dimensions increase, the more ranges need to be transferred. Regular sections with strides is the second access method. For each dimension, a lower bound, upper bound, and stride are specified. This allows a compact representation using n tuples for access to an n-dimensional array.
The method of data sieving described in section 2.5.1 is also crudely made use of in the Jovian system. Each coalescing processor sorts the list of blocks requested from it to convert them into a single disk operation. Jovian has a value called the Read Gap Size which functions to specify the maximum number of unused data elements between the requested elements it is acceptable to read. The PASSION system appears to make better use of the sieving method however.
The algorithm for one of the test applications was to read an N x N distributed, structured grid from disk using PAP application processors and PCP coalescing processes. The distribution of coalescing processors to application processors was block oriented, row major order. Performance results are given in table 4. The rate at which the application processor receives data is found in column 3. The data rates obtained by the Jovian library are better than doing replicated reads, but they are nowhere near the theoretical maximum.
+------------+-------------+---------------+-----------------+------------+ |Global Grid | Disk Read | Jovian Gather | Replicated Read | % Overhead | | +-------------+---------------+-----------------+ | | Size | ms(MB/sec) | ms(MB/sec) | ms(MB/sec) | | +------------+-------------+---------------+-----------------+------------+ | 1K x 1K | 1000 (2.2) | 1700 (1.2) | 1900 (1.1) | 44.3 | +------------+-------------+---------------+-----------------+------------+ | 2K x 2K | 3700 (2.3) | 6600 (1.3) | 9600 (.0) | 43.4 | +------------+-------------+---------------+-----------------+------------+ | 4K x 4K | 14600 (2.3) | 24300 (1.4) | 36800 (.9) | 39.8 | +------------+-------------+---------------+-----------------+------------+
Table 4: Jovian performance and overhead for a structured grid [BBS+94]
The second example is using the regular section access method with a structured grid. Several sub-matrices of a given distributed matrix were read from disk. This template was meant to model a geographic information system application for computing the amount of vegetation there is on the ground from multiple satellite images. The average data transfer rate to the application processors is only about 0.4 to 1 MB/sec. The factors affecting this transfer rate are load imbalance and the data access pattern. This is an unstructured algorithm, which means that the data access patterns are difficult to predict and are non-contiguous, leading to many disk transfers. For some nodes, the time using the Jovian library is approximately equal to the time to do replicated reads. On others, there is a significant speedup. In no case does the Jovian library perform worse than replicated read so it is an improvement.
The Jovian system seems to essentially be a subset of the PASSION system. All of the operations described by the library are operations that can be accomplished using the PASSION library as well. Additionally, the PASSION system provides additional functionality not available in the Jovian system. The Jovian system lacks a clean model for representing user data and moving between it and the disk. Whereas the PASSION system specifies things like ICLA and OCLA and describes the interplay between them, the Jovian system only mentions coalescing processes which massage the data between application and disk storage formats.
It's difficult to compare the two libraries because both of them used different algorithms to test, and they all ran on different hardware. However, from figure 6 it is clear that the Jovian library has a large overhead, accounting for around 40% of the access time. I was unable to find similar numbers for the PASSION system, though the feeling I get is that it is lower than that. I base my feeling on several things. The PASSION system doesn't just implement the coalescing methods, it also does other optimizations such as data prefetch and data reuse that the Jovian library doesn't do. Also, the PASSION implementation of data sieving seems more complete than the Jovian version.
The parallel I/O technique described in this paper achieves up to 93% of peak disk bandwidth usage. The Jovian system utilizes at most 60% of the disk bandwith. 40% is library overhead. Disk directed I/O is specifically designed for high performance on parallel scientific algorithms. It is most suited for MIMD multiprocessors that have a distinction between I/O processors (IOPs) and compute processors. Both the PASSION and Jovian systems make the same assumptions, though the PASSION systems is much more flexible than Jovian. Additionally, the technique is best suited to a SPMD programming model (described earlier). With this method, compute processors send a single request to all I/O processors which then optimize the passage of data between disk, buffer, and the communications network.
In most multiprocessor systems, when a processor wants to load data from a file, it makes a filesystem request which often will result in non-contiguous access, especially if the file is spread across multiple I/O processors, in which case the request will be broken down into several smaller pieces. A major difficulty for the filesystem is to recognize these requests that have been split up as a single request and use that information to optimize the I/O. Using a Collective I/O method, all the compute processors cooperate to make a single, large request. This method retains the semantic information that is lost by the split-it-up method.
There are three ways to implement collective I/O. Traditional caching, which mimics traditional caching methods. TwoPhase I/O, as described in section 3 is where the data is permuted among the compute processors by a permutation algorithm that massages the data into the right format. The third method is Disk-directed I/O. This essentially puts the I/O processors in control of the order and timing of the flow of data.
Disk-directed I/O has several performance advantages:
+ The I/O can conform not only to the logical layout of
the file, as in two-phase I/O, but the physical layout
on disk.
+ The disk-I/O phase is integrated with the permutation
phase.
+ There is only one I/O request to each IOP; subsequent
communication uses only low-overhead data transfer mess-
ages.
+ Disk scheduling is improved, possibly across
megabytes of data.
+ Prefetching and write-behind require no guessing, and
thus make no mistakes.
+ Buffer management is perfect, needing little space
(two buffers per disk file), and capturing all poten-
tial locality advantages.
+ There is no communication among the IOPs and none,
other than barriers, among the CPs. The cost of these
barriers is negligible compared to the time needed for
a large file transfer.
[DK94]
Kotz implemented both a traditional caching system and disk directed I/O in order to do a comparison between them. He didn't implement two-phase I/O, because disk-directed I/O obtains better performance than two-phase I/O. Disk directed I/O sustained between a 6.0 and 8.0 MB/s transfer rate for accesses both small and large, hovering around 6.0 MB for reads and 8.0 MB for writes. On the average, disk-directed reading moved about 32.8 MB/s out of the maximum transfer rate of 37.5 MB/s for the 16 simulated disks.
Traditional caching was unable to use the full disk bandwidth, and performed poorly for 8-byte record sizes. There were some cases in which traditional caching matched disk-directed I/O, other cases were up to 16.2 times slower. Traditional caching failed because of the following problems. If compute processors were active at different locations, the multiple localities caused a significant performance loss because the disk access wasn't contiguous. Some patterns caused prefetching mistakes. For small cyclic patterns, many small non-contiguous records were thrown around, causing many disk accesses. Finally the cache management overhead itself played a part in the downfall of traditional caching.
The reason that disk-directed I/O performs better than twophase I/O is because there is no need to choose a conforming distribution. The design of two-phase I/O calls for either a row-major or column-major order storage format. Kotz claims his results show that this format was rarely the best choice. Also, disk-directed I/O does disk-request presorting which obtains a 40-50% performance improvement. Since there are no prefetching mistakes, there is no cache thrashing. Very importantly, no permutations are done on the data at the compute processors, so no extra memory is needed, and the permutation phase is overlapped with I/O. Each piece of data moves through the system only once in disk-directed I/O, and usually twice in two-phase I/O. Finally, communication is spread throughout the disk transfer, not concentrated during the permutation phase. The results indicate that disk-directed I/O avoids many of the problems with traditional caching.
Disk-directed I/O seems to perform comparably with PASSION, and does much better than Jovian. Jovian was only able to achieve about 60% of the maximum transfer rate, whereas disk- directed I/O was able to achieve up to 93%. The disadvantage is that disk-directed I/O depends on a MIMD system with distinctions between I/O processors and compute processors. PASSION doesn't have this limitation.
PASSION seems to be the most effective parallel file I/O package, with disk-directed I/O coming in second followed by Jovian third. Each package has some advantages and disadvantages. Jovian seems to be functionally a subset of PASSION, in that all the features described are contained within PASSION, plus PASSION has additional features. Disk directed I/O has major advantages for MIMD/SPMD systems. However, the main drawback is that each node has to synchronize with the other nodes during reads, thus losing some of the benefits of MIMD operation.
Perhaps one of the most significant advantages of PASSION over the other two systems is its portability. It makes minimal assumptions about the architecture of the machine, just that it has some disks, and some way to communicate with other nodes. The portability of the PASSION system will win out over other systems that may be slightly faster for some operations, but are machine specific.
[BBS+94] R. Bennett, K. Bryant, A. Sussman, R. Das, J. Saltz, "Jovian: A Framework for Optimizing Parallel I/O", Proceedings of the Scalable Parallel Libraries Conference, pages 10-20. IEEE Computer Society Press, October 1994. (ftp://hpsl.cs.umd.edu/pub/papers/splc94.ps.Z) [CBH+94] A. Choudhary, R. Bordawekar, M. Harry, R. Krishnaiyer, R. Ponnusamy, T. Singh, R. Thakur, "PASSION: Parallel And Scalable Software for Input-Output", Technical Report SCCS-636, ECE Dept., NPAC and CASE Center, Syracuse Univer- sity, September 1994. (ftp://erc.cat.syr.edu/ece/choudhary/PASSION/passion_report.ps.Z) [DK94] D. Kotz, "Disk-directed I/O for MIMD Multiprocessors", Tech- nical Report PCS-TR94-226, Department of Computer Science, Dartmouth College, November 1994. (ftp://ftp.cs.dartmouth.edu/pub/CS-papers/ Kotz/kotz:diskdir.ps.Z) [WGR+93] D. E. Womble, D. S. Greenberg, R. E. Riesen, S. R. Wheat, "Out of Core, Out of Mind: Practical Parallel I/O", Proceedings of the Scalable Parallel Libraries Conference, pages 10-16. Mississippi State University, October 1993. (ftp://ftp.cs.sandia.gov/pub/papers/ dewombl/parallel_io_scl93.ps.Z) [BCK+95] R. Bordawekar, A. Choudhary, K. Kennedy, C. Koelbel, M. Paleczny, "A Model and Compilation Strategy for Out-of-Core Data Parallel Programs", Proceedings of the Fifth ACM SIGPLAN Symposium on Principles and Practice of Parallel Program- ming, pages 1-10, July 1995. (ftp://www.cacr.caltech.edu/techpubs/PAPERS/cacr104.ps)